
这个模板的核心功能是解决两个问题:
1, 有效的提示词(prompt)
这个需要根据实际业务场景多次调整。
2, 批量提问并回填
将多个提问词一次提交,这样以节约token费用。这时会有个情况就是chatgpt 返回是一堆翻译结果,需要从里面清洗下,以正确匹配其前面的提示词。
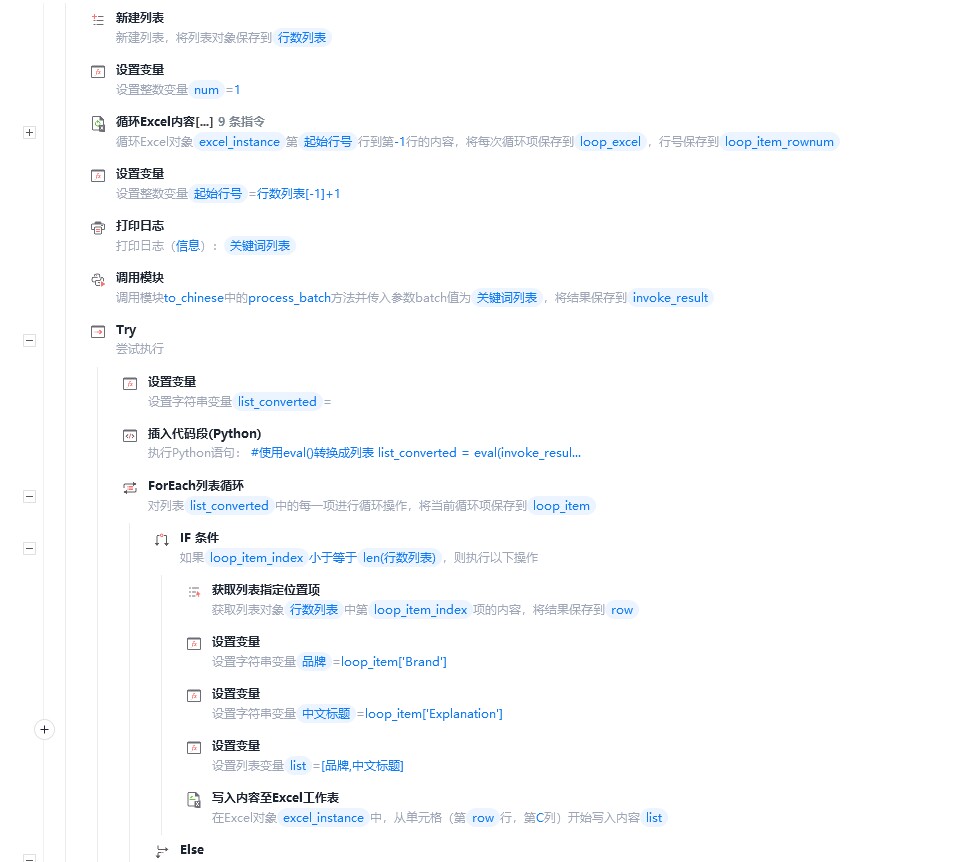
点击可放大
影刀这里只负责读取excel表格里的标题,并批量作为参数提供给chatgpt,然后将chatgpt返回的翻译结果逐行回填到excel文件里。
chatgpt翻译部分由影刀自带的python模块来完成。
其代码如下(代码是实现将标题翻译并提取品牌词,其他根场景需要做调整):
import json
import re
import requests
API_BASE_URL = "https://xxxx" #chatgpt接口地址
API_KEY = "****" #chatgpt密钥
def extract_potential_brands(explanation):
brand_candidates = []
words = explanation.split()
non_brand_terms = [
"for", "women", "men", "kids", "children", "hour", "hours", "day", "night",
"skin", "care", "beauty", "makeup", "cosmetics", "fragrance", "perfume",
"region", "area", "extract", "formula", "hydrating", "moisturizing",
"nourishing", "face", "body", "hair", "nail", "anti-aging", "whitening",
"brightening", "firming", "product", "crowd", "skin type", "efficacy",
"ingredient", "raw material", "texture", "consistency", "budget",
"price range", "local", "domestic", "foreign", "imported", "exported", "online",
"offline", "cheap", "expensive", "affordable", "brand", "line", "series",
"natural", "organic", "vitamin", "aloe", "jojoba", "essential", "oil", "herbal",
"botanical", "mineral", "sunscreen", "lotion", "cream", "serum", "mask", "peel",
"cleanser", "toner", "exfoliant", "moisturizer", "conditioner", "shampoo"
]
for word in words:
if re.match(r"^[A-Za-z][a-zA-Z0-9]*$", word) and word.lower() not in non_brand_terms:
response = requests.get(f"{API_BASE_URL}/gpt-3/eng-check", params={"text": word}, headers={"Authorization": f"Apikey {API_KEY}"})
data = response.json()
if "not_found" in data:
brand_candidates.append(word)
for i in range(len(words) - 1):
combined_word = words[i] + words[i + 1]
if re.match(r"^[A-Za-z][a-zA-Z0-9]*$", combined_word) and combined_word.lower() not in non_brand_terms:
response = requests.get(f"{API_BASE_URL}/gpt-3/eng-check", params={"text": combined_word}, headers={"Authorization": f"Apikey {API_KEY}"})
data = response.json()
if "not_found" in data:
brand_candidates.append(combined_word)
brand_candidates = list(set(brand_candidates))
valid_brands = [brand for brand in brand_candidates if len(brand) > 1]
return valid_brands
def process_batch(batch):
messages = [
{
'role': 'system',
'content': (
'你是一名专门从事美容和个人护理电子商务的翻译。请将东南亚语言的产品关键词用英文理解并输出中文,确保翻译地道且符合当地文化习惯。'
'特别强调,如果原文是马来西亚文,有可能会有拼写错误,请尽可能理解本意再翻译。'
'每个回复应包括两个字段:Brand(品牌)和Explanation(翻译+解释)。将包含个人姓名或独特词语且与化妆品无关的术语视为品牌,将品牌名输出英文;'
'如果没有品牌,则输出“-”。回复应格式化为单个JSON对象,不包含序列号,仅包含指定的字段。'
'确保标点符号符合Python标准,并提高品牌检测的可靠性。'
'请结合上下文和整体语境来判断品牌,排除人群、产品成分、地区、部位和功效等合理词汇。品牌通常是原文意境不符时判断为品牌。'
'如果某个词看起来像品牌但与整体内容不符,请将其识别为品牌。'
'请确保结果不包含“需进一步检查和验证翻译准确性”的注释,并一次性返回地道且准确的翻译结果。'
'如果理解,请回复:好的,我会使用美容和个人护理电子商务的专门术语进行翻译,并严格按照示例格式及JSON格式回复,不添加任何多余的符号,不作任何解释.示例只做参考,不返回示例。'
)
},
{
'role': 'assistant',
'content': '好的,我会使用美容和个人护理电子商务的专门术语进行英文理解并输出中文,并严格按照示例格式及JSON格式回复,不添加任何多余的符号,不作任何解释示例只做参考,不返回示例。'
}
]
example_content = {
'role': 'assistant',
'content': json.dumps([
{
"Brand": "nings",
"Explanation": "nings正品面膜霜:一种护肤产品,专为滋养和增强皮肤外观而设计,其特殊配方的面霜。"
},
{
"Brand": "-",
"Explanation": "夏日之翼 Wow:可能描述夏季的活动或产品,如夏季化妆品或活动,强调惊人的效果或特色。"
}
], ensure_ascii=False)
}
messages.append(example_content)
keywords_content = "\n".join(batch)
messages.append({'role': 'user', 'content': keywords_content})
response = chat_with_gpt(messages)
cleaned_response = clean_response(response)
analyzed_response = analyze_response(cleaned_response)
print("翻译结果:", analyzed_response)
return analyzed_response
def chat_with_gpt(messages):
try:
response = requests.post(
API_BASE_URL + "/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
},
data=json.dumps({
"model": "gpt-4o",
"messages": messages,
"max_tokens": 4000,
"temperature": 0.2,
"top_p": 0.3,
"stop": None
})
)
response.raise_for_status()
resp_content = response.json()["choices"][0]["message"]["content"]
return resp_content
except requests.exceptions.RequestException as e:
return f"Error: {e}"
except json.JSONDecodeError as e:
return f"JSON Decode Error: {e}"
except KeyError as e:
return f"Key Error: {e}"
def clean_response(response):
response = response.strip()
try:
if response.startswith("```json"):
response = response[7:]
if response.endswith("```"):
response = response[:-3]
json_object = json.loads(response)
return json_object
except json.JSONDecodeError:
return f"Invalid JSON response: {response}"
def analyze_response(response):
if isinstance(response, str):
return response
if not isinstance(response, list):
return "Invalid format: response is not a list of objects"
for item in response:
if 'Brand' not in item or 'Explanation' not in item:
return "Invalid format: missing Brand or Explanation fields"
if item['Brand'] == "-":
potential_brands = extract_potential_brands(item['Explanation'])
if potential_brands:
item['Brand'] = potential_brands[0]
else:
item['Brand'] = "-"
item['Explanation'] = re.sub(r"(需进一步检查和验证翻译准确性)", "", item['Explanation'])
return json.dumps(response, indent=2, ensure_ascii=False)